In Part 1, we discussed in a first step the ground barrier for taxing data in the context of international taxation: a proper definition of data. In a second step, we showed you which negative effects result from the trilemma of data-based taxation approaches. In part 2, we want to present possible solutions on how to tax data-driven businesses in a third step.
How to tax data-driven businesses
So, how can we tax data-driven businesses and meet all the criteria of the trilemma (see part 1) simultaneously? Previous solution strategies suggest either a purely quantitative or qualitative methodology.
Quantitative methodology
Like electric meters, counting the amount and use of electricity flowing through a household, with application programming interfaces as bites & bytes meters, it should already be possible to quantitatively measure the amount and use of data sent cross-borderly within an MNE (and probably even count the underlying user interaction). This first counting step could act in order to assign them to the respective state in a second step. But in this case, above all respective to personal data, a personal data breach seems to be tricky to avoid. Plus: Do we really want to demand from MNE to collect even more data just for the sake of taxation?
Qualitative methodology
Equally conceivable is a taxation approach that considers the underlying algorithm itself in the form of a purely qualitative methodology. In this formal-technical methodology, data would be assigned to countries according to the weighting of the respective algorithm.
However, it remains questionable how a corresponding allocation of value-added contributions should be possible. The idea of only one algorithm to determine is simply wrong. If we think of an MNE more like an ecosystem or an all-over connected organism, the underlying processes are not made possible by just one mega artificial intelligence. In fact, the term artificial intelligence is highly disputed, because we tend to think about just one super machine brain orchestrating e.g. the google empire. But for each application there are countless algorithms (or processes — Dr. Niekler as our computer science expert in the team does not get tired of pointing out the flawed tax lawyers´ terminology).
Additionally, the idea of weighting a person’s data might not only tricky, but also eventually ends in a breach of this person´s privacy sphere. And even if possible without, we need to ask our self: are businesses and tax authorities around the world capable of such a technical challenge? And isn´t the underlying weighting of the algorithm not an essential part of the MNE´ business secret?
A mixture of both
So, taxing the digitalized economy ends here? Well, we actually started with this unsatisfactory situation in the beginning. But if we accept the permanent establishment as a fixed principle, and if we assume that broadening the definition of it might not be a bad solution (highly disputed, but due to a lack of space nothing to discuss here), we also thought: this cannot be the answer.
Therefore, we propose a process-oriented approach that could make it possible to meet the criteria of the trilemma — localization, value creation, and control — away from the over-sophisticated focus on user- and algorithm-specific details.
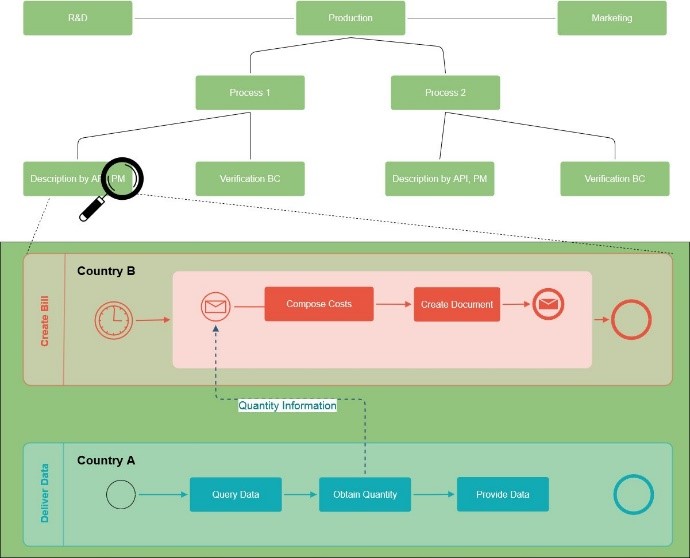
Just conceptualize the cross-border services of a data-driven MNE with its regular functions like research & development, production and marketing. What happens if it is possible to divide e.g. the production function in separate processes and describe them by process mining, count them by application programming interfaces, and verify them by blockchain methods? In this case, the transparency of the extraction and utilization of data might result in tracking exact locations within the value chain.
In this case, we use the Business Process Model Notation 2.0 (BPMN) as the central tool for the documentation of digital goods and services. As a form of process mining, BPMN describes all processes involved in the value chain. To make it more understandable: BPMN is a business analyse tool that provides a graphical notation for specifying business processes. In other words — with BPMN, you can transform your business in figures and diagrams for the use of everyone. Those processes as describer in turn need anchor points of the business models — which can be provided by application programming interfaces as counter of bites & bytes and the underlying user interaction (remember the electric meter comparison above).
Now imagine you can compare those processes within the MNE functions and (!) different MNE from a tax authority perspective. Even on a very abstract level, without the breach of private sphere or business secrets, you can at least describe those processes, e.g. one of Amazons´ and one of Alphabets´ function. Even if those businesses might have different underlying businesses cases, you will find a R&D function, a marketing function, or a production function. So, what happens, when those functions are basically working the same way, at heart all driven by the same amount of data and the similar integrated software? They might be made comparable. And comparability is something very useful in the world of transfer pricing and its hard-to-value-intangibles.
However, whether this process-oriented application can meet all the requirements of the trilemma remains open and requires further research. In particular, the authors therefore aim at a comparison with another, intensively discussed methodology,[1] which should allow a comprehensive transparency: The logging of individual transactions by a block chain network. In these networks, the participants confirm each other manipulations of data (transactions) in encrypted data blocks. The participants can be companies, (government) organizations or private individuals.
Outlook: One of the million digital documentation tools hopefully helps
Still, in the end it remains an open question if this trend to digital documentation will raise efficiency, neutrality or even distributive justice.
The first step would be for MNE to heavily implement more of those audit tools in their transfer pricing approach. The barrier for this might not be as high as it sounds, because e.g. process mining is a tool MNE have been using for decades in valuing the performance of their supply chain. But if they want to share this information of their precise internal transfer pricing with externals like tax authorities around the globe is hard to imagine – at least not without any incentives.
But to gain advantage as a digital frontrunner, this should maybe count independently from the question, if international organizations like the OECD proposing this idea and the central tax authorities are willing and maybe even rewarding this effort by e.g. minimising the burden of proof. Of course, this is under the condition, that tax authorities can even establish a trusted system where data can be controlled. Additionally, they actually must be capable of following this trend to digital transfer pricing systems. A possible digital gap between developed and developing nations as well as current international tensions regarding the function of free trade might be heavy barriers for implementing new digital documentation standards.
Considering the ongoing offers of the BIG4 and Start-Ups, which are almost daily launching new digital documentation tools, there is hope that many firms will implement those tools by their own and advance the transfer pricing system with the needed digital elements to tax data properly.
*****************************************************************
* The team to tax data:
Jan Winterhalter is a tax lawyer & PhD cand. in International taxation at the Institute for Tax Law under Professor Dr. Marc Desens and a research fellow & scholar of the Heinrich Böll Foundation. His resent research at the crossroads of economy, philosophy & computer science revolves around current reforms of the International Tax System with focus in data-driven business models and the digital nexus. He is currently working on digital documentation systems using process mining and blockchain methods. For more information, see https://www.researchgate.net/profile/Jan_Winterhalter and http://www.cluster-transformation.org/en/start.
Andreas Niekler is a research assistant & computer science lecturer at the Institute of Computer Science at the University of Leipzig, who works, among other things, in the project group “Data Mining and Value Creation”. He studied Media Technology at HTWK Leipzig and the University of West Scotland. After two years working as a freelance Programmer and lecturer at the Leipzig School of Media, he joined the NLP group at the University of Leipzig. During his doctorate, he used Bayesian models and clustering techniques to analyse, how topics can be captured within texts. Within his research at Leipzig University he created and successfully published novel approaches, methodologies and interfaces to make large digital text collections accessible to content analysis research, see http://asv.informatik.uni-leipzig.de/en/staff/Andreas_Niekler.
Together, they established the idea of this trilemma (which has its origins in the article Winterhalter/Niekler, Digitax 2020, Vol.1 p.49-53), see https://processtax.github.io/, more
Contact via jan.winterhalter@uni-leipzig.de
[1] Pistone / Weber, Taxing the Digital Economy, The EU Proposals and Other Insights, 2019, p. 307, whose last chapter-headline is illustratively “The Blockchain Revolution for Transfer Pricing Documentation: If Not in 2020, Then When?.
________________________
To make sure you do not miss out on regular updates from the Kluwer International Tax Blog, please subscribe here.

